The implementation of stacks using arrays is very simple:
class ArrayStack
{
private Object[] array;
private int count;
public static final int MAX = 100;
public ArrayStack()
{
array = new Object[MAX];
count = 0;
}
public Object top()
{
return array[count-1];
}
public void pop()
{
count--;
}
public void push(Object obj)
{
array[count++]=obj;
}
public boolean isEmpty()
{
return count==0;
}
}
When a new stack is created (via the constructor) its array is set to
the maximum size which it is considered the stack would ever grow to
(in our example, set to 100), and its count field is
set to 0.
Pushing a new object onto the stack involves setting the array cell indexed
by the count to refer to the new object and then increasing the count
by one. Popping an object off the stack involves just reducing the count
value by one. There is no need to do anything else to delete the object,
since that cell will be set to another object if push is
used again. The cell which is indexed by the count field less 1 refers
to the top item of the stack.
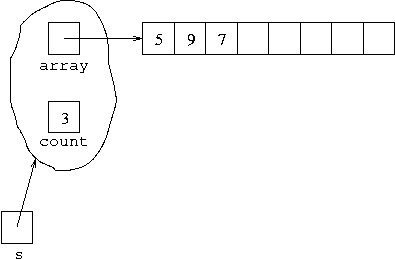
For example, if we executed:
Stack s = new Stack(); s.push(5); s.push(9); s.push(7);assuming that our type
Stack here refers to a stack of
integers implemented with an array, the situation arrived at could be
represented as:
Then after executing
s.push(8);the situation will be:
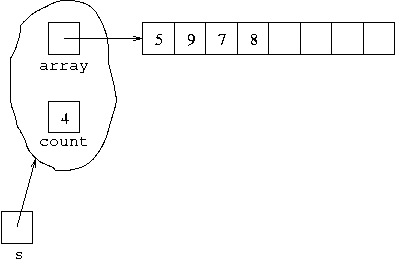
After executing
s.pop();it becomes:
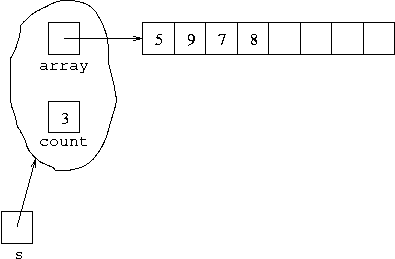
and then after executing
s.push(11);it becomes
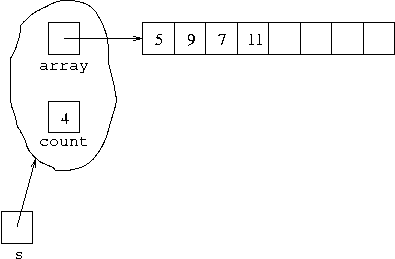
The advantage of using an array implementation for a stack is that it is more efficient in terms of time than a linked list implementation. This is because there is none of the work associated with claiming new store as the size of the stack increases and garbage collecting it as it reduces. Rather there is a fixed amount of store set aside from the start for the stack. As stacks are destructive we do not have to copy this store every time we perform a stack operation, and in general in the sort of applications where stacks are used we do not have large numbers of them, so there is not a big issue of waste of store.
class ArrayQueue
{
private int front,back;
private Object[] array;
public static final int MAX=100;
public ArrayQueue()
{
front=0;
back=0;
array = new Object[MAX];
}
public Object first()
{
return array[front];
}
public void leave()
{
front++;
if(front==MAX)
front=0;
}
public void join(Object obj)
{
array[back++]=obj;
if(back==MAX)
back=0;
}
public boolean isEmpty()
{
return front==back;
}
}
With stacks, the push method caused the single index field
count to be increased by one, while the method pop
caused it to be decreased by one. With queues, however, the two index fields,
front and back, can each only be increased by one.
The field front is increased by one by the leave
method, while the field back is increased by one by the
join method. So as items leave and join the queue, the section
of the array used to store the queue items will gradually shift along the
array and will eventually reach its end. This is different from stacks,
where the section of the array used to store the items in a stack only
reaches the end of the array if the size of the stack goes beyond the
size of the array.
To deal with this problem, a "wraparound" technique is used with queues
implemented with arrays. When either the front or
back field is increased to the point where it would index
past the end of the array, it is set back to 0. Thus the state is reached
where the front section of the queue is in the higher indexed section of the array
and the back section of the queue in the lower indexed section of the
array. Consider, for example, a ArrayQueue variable,
q, referring to the structure in the diagram below:
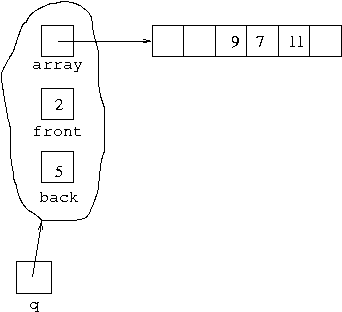
This represents the queue [9,7,11]. The contents
of the rest of the array are irrelevant since the queue is the section of
the array between that indexed by the front field of the
object referred to by q up to but not including the array
cell indexed by back. If after this
q.leave();is executed, the first item in the queue leaves it, giving the situation:
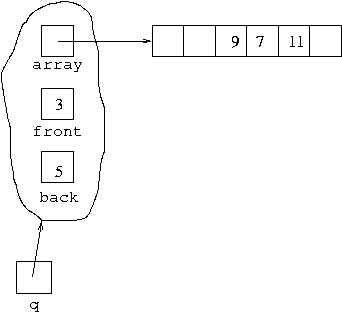
This represents the queue [7,11]. Note that it
was not necessary to change the value of the array cell that stores
9. Changing the value of the front
field indicates that 9 is no longer in the
queue which now starts at the cell in the array indexed by 3.
Suppose the array is of length exactly 6, as shown in the diagram. So the
static final int value MAX would be set to
6 rather than 100 as in our code. In this
case when an item joins the queue in the state as represented above,
increasing back by one causes it to become equal to
MAX so it is then set to 0. So, for example,
executing
q.join(8);changes the above situation to:
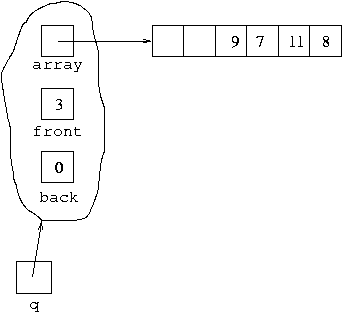
The variable q now refers to an object that represents the
queue [7,11,8]. If another item joins the queue,
for example, after executing
q.join(10);the queue will wrap around the array:
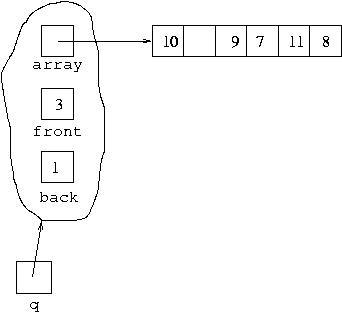
This represents the queue [7,11,8,10].
The main reason for showing an implementation of lists using arrays is just to indicate that a list as an abstract data type is not equivalent to a linked list. One is an abstract concept, the other is a structure given by cells and pointers in the computer. Because the abstract concept is generally implemented using one particular data structure does not mean the two are equivalent because it is possible to implement the abstract concept in other ways.
Here is an array implementation of lists of integers:
import java.util.*;
class ArrayList
{
private int count;
private int[] array;
public static ArrayList empty()
{
return new ArrayList(null,0);
}
private ArrayList(int[] a,int s)
{
array=a;
count=s;
}
public int head()
{
return array[count-1];
}
public ArrayList tail()
{
return new ArrayList(array,count-1);
}
public ArrayList cons(int n)
{
int[] array1 = new int[count+1];
for(int i=0; i<count; i++)
array1[i]=array[i];
array1[count]=n;
return new ArrayList(array1,count+1);
}
public boolean isEmpty()
{
return count==0;
}
public String toString()
{
if(count==0)
return "[]";
else
{
String str="["+array[count-1];
for(int i=count-2; i>=0; i--)
str+=","+array[i];
return str+"]";
}
}
public static ArrayList fromString(String str)
{
str=str.trim();
if(str.charAt(0)!='['||str.charAt(str.length()-1)!=']')
return empty();
str = str.substring(1,str.length()-1);
StringTokenizer toks = new StringTokenizer(str,",");
try {
int[] array1 = new int[toks.countTokens()];
for(int i=array1.length-1; i>=0; i--)
{
String num = toks.nextToken().trim();
array1[i]=Integer.parseInt(num);
}
return new ArrayList(array1,array1.length);
}
catch(NumberFormatException e)
{
return empty();
}
}
}
Lists here are represented in a similar way to our stack representation
using arrays, as a partly filled array with a count showing the amount
of the array which is treated as data in the list. The head of the
list, like the top of a stack, is the item in the array indexed by one
less than the count. This means that the tail method
can be implemented like pop with stacks, sharing the
array but with a reduced count. However, since lists are constructive,
a new object with the reduced count is created. So if we have three
list variables l1, l2 and l3, the
following shows l1 representing the list
[9,7,6,8]:
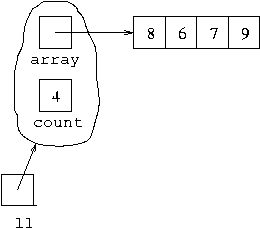
Now if we execute
l2 = l1.tail();we get:
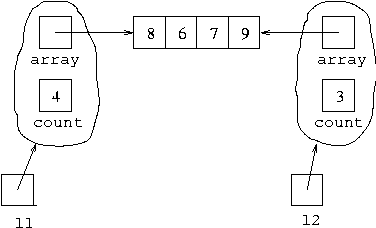
So l2 represents [7,6,8] while
l1 still represents [9,7,6,8].
But the cons operation has to be done by copying all the
elements of the list it is called on. If from the above we execute
l3 = l2.cons(20);we get the situation:
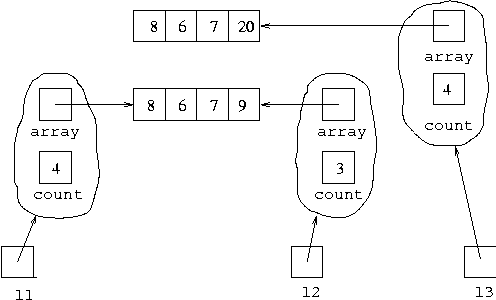
Now l3 represents [20,7,6,8].
We can't put 20 into the array for l2,
making the situation:
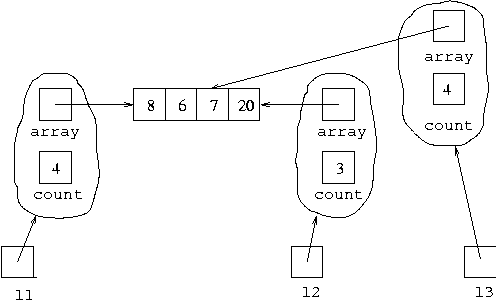
since this would change l1 into also referring to
[20,7,6,8]. This cannot be right, because
our abstract lists are defined so they can't be changed at all once
created, let alone as a side-effect to some other operation.
Last modified: 18 April 2005