Trees and Enumerations
In the previous notes and lab exercises you have seen how to build lists
and stacks using the basic abstract linked list data structure. These
notes will introduce another very common data structure -- the binary
tree.
Source code for the programs in the notes can be found in the directory
/import/teaching/BSc/1st/ItP/Trees/
, assuming that you are reading this on a UNIX PC in the ITL.
The Binary Tree data structure
The list structures that you are already familiar with can be considered
as a kind of `dynamic' array type; that is, a list (or stack) stores a
simple linear sequence of data, but unlike an array a list can grow or
shrink to accomodate the amount of data in it at any one time. As you
know, you can even implement linked list structures using arrays, although
it is awkward to make the dynamic resizing work properly when your array
capacity is exceeded (think about how you might achieve this with your
array-based Stack classes from Assignment 2).
The binary tree is a somewhat different beast, as it stores data
in a two-dimensional structure with some interesting properties. The
diagram below shows a small binary tree storing four integer
values:
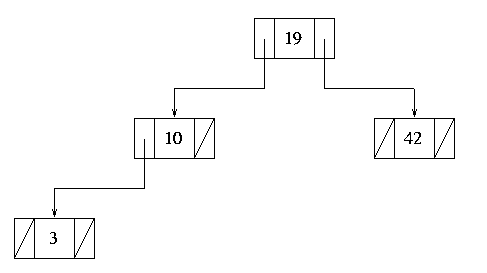
Figure 1.
As you can see, the tree is constructed from linked nodes in a similar
fashion to the familiar lists and stacks, where each node contains some
data (in this case an integer value) and pointer(s) to other node(s) of
the tree. It should be obvious to you why this structure is known as a
binary tree: each node contains pointers to two further nodes, although of
course either or both of these references may be null. Other
types of tree structure exist, differing mainly in the amount of data and
number of node pointers maintained by each node.
Trees in computer science are a bit like family trees, in that they are
usually drawn `upside down'. Thus, we will refer to the node at the `top'
of the tree as the root node, and those at the `bottom' (i.e. those
that do not point to any other nodes) as leaf nodes. Any node that
is not a leaf node is by definition and interior node of the tree.
In the diagram above, the node containing the value 19 is the
root node, the nodes 19 and 10 are interior
nodes and the nodes 3 and 42 are the leaves.
Since any tree node be be treated as the root node of a smaller
tree, we can talk about the left and right subtrees of a
node N; that is, the trees whose root nodes are pointed to by
the left and right hand node pointers of N.
This notation is reflected by the Java implementation of the tree
structure given below:
1 /**
2 * A simple binary tree class, storing integers
3 */
4 public class BinaryTree {
5
6 /** The data item in this node */
7 protected int data;
8
9 /** The left-hand subtree (LHS) */
10 protected BinaryTree left;
11
12 /** The right-hand subtree (RHS) */
13 protected BinaryTree right;
14
15
16 /** Create a tree */
17 public BinaryTree(int data) {
18 this.data = data;
19 left = null;
20 right = null;
21 }
22
23
24 /** Get the data in the root node */
25 public int data() {
26 return data;
27 }
28
29 /** Get the LHS */
30 public BinaryTree left() {
31 return left;
32 }
33
34 /** Get the RHS */
35 public BinaryTree right() {
36 return right;
37 }
38 }
Each instance of the class BinaryTree forms the root of a
binary tree, with its left and right subtrees pointed to by the instance
variables left and right respectively. The code
below shows how you might construct the tree in Figure 1 using the
BinaryTree class:
1 public class TreeTest {
2
3 public static void main(String args[]) {
4 BinaryTree tree = new BinaryTree(19);
5 tree.left = new BinaryTree(10);
6 tree.right = new BinaryTree(42);
7 tree.left.left = new BinaryTree(3);
8 }
9 }
This is all very well, but it doesn't immediately seem to be much use;
after all, we could store the same data just as easily in a list or an
array. Look more closely at the tree in Figure 1 though, and you will
notice that whichever node you choose, the values stored in its left
subtree are always less than the value stored in the node itself,
while the values in the right subtree are always greater than the
node value. Very convenient, but again, what use is it? Consider the
problem of searching for a particular data value stored in the tree: if
you know nothing about the arrangement of nodes in the tree, you might
have to examine every node of the tree before finding the sought value, or
concluding that it was not present. This is an O(N) search, similar to
searching an unordered list. If however, the tree is arranged according
to the scheme described above, we can make the search much more efficient.
Say we are looking for the value 3. We begin by examining
the root node, and noticing that 3 is less than 19. Therefore, if the
value 3 is in the tree anywhere, it must lie within the left
subtree of the root node (recall that all values in the left subtree are
less than the value of their parent). So the search proceeds to the root
of the left subtree, in this case the node containing the value
10. 3 is less than 10, so again we follow the left hand
pointer, and this time find the node we are looking for. This search
required a total of three comparisons between node values, rather than the
four that might have been needed for a brute-force search. In fact, the
number of comparisons needed for a search of this kind depends
height of the tree rather than the absolute number of nodes, where
the height is the length of the longest path from the root node to a leaf
node, plus one. For larger trees, the difference will be much greater and
the searches consequently much more efficient. Note that you can achieve
the same degree of speedup when searching an ordered list -- your
Introduction to Algorithms notes should have much more to say on this
topic.
Adding and searching for nodes
You have probably noticed that I haven't yet mentioned how to get the
nodes into this nice arrangement in the first place. The class below is
an enhanced version of the simple BinaryTree above, with
additional methods for searching and adding new nodes to the tree.
1 /**
2 * A simple binary tree class, storing instances of OrderedObject.
3 */
4 public class BinaryTree {
5
6 /** The data item in this node */
7 protected OrderedObject data;
8
9 /** The left-hand subtree (LHS) */
10 protected BinaryTree left;
11
12 /** The right-hand subtree (RHS) */
13 protected BinaryTree right;
14
15
16 /** Create a new empty tree */
17 public BinaryTree() {
18 data = null;
19 left = null;
20 right = null;
21 }
22
23
24 /** Get the data in the root node */
25 public OrderedObject data() {
26 return data;
27 }
28
29 /** Get the LHS */
30 public BinaryTree left() {
31 return left;
32 }
33
34 /** Get the RHS */
35 public BinaryTree right() {
36 return right;
37 }
38
39
40 /**
41 * Insert a new data item into the tree. This will fill an empty (data ==
42 * null) node if it finds one, otherwise a new node is created. The data is
43 * always inserted in sorted order, using compareTo().
44 * Throws a TreeException if a matching object is already present.
45 */
46 public void insert(OrderedObject newData) throws TreeException, OrderedObjectException {
47 if (data != null) {
48 int a = newData.compareTo(data);
49 if (a < 0) {
50 if (left == null) {
51 left = new BinaryTree();
52 }
53 left.insert(newData);
54 }
55 else if (a > 0) {
56 if (right == null) {
57 right = new BinaryTree();
58 }
59 right.insert(newData);
60 }
61 else {
62 throw new TreeException("Object "+newData+" is already in the tree!");
63 }
64 }
65 else {
66 data = newData;
67 }
68 }
69
70 /**
71 * Find a data item matching target in the tree. Returns a subtree with the
72 * matching item as its root, or null if no match was found.
73 */
74 public BinaryTree find(OrderedObject target) throws TreeException, OrderedObjectException {
75 if (data != null) {
76 int a = target.compareTo(data);
77 if (a < 0) {
78 return (left == null) ? null : left.find(target);
79 }
80 else if (a > 0) {
81 return (right == null) ? null : right.find(target);
82 }
83 else {
84 return this;
85 }
86 }
87 else {
88 return null;
89 }
90 }
91
92
93 /** Generate a printable representation of the root node of the tree. */
94 public String toString() {
95 if (data != null) {
96 return data.toString();
97 }
98 else {
99 return null;
100 }
101 }
102 }
Before we examine the algorithms used by the insert and
find methods, let's take a closer look at the data stored by
this class. The tree searching algorithm is based around the idea of one
data item being `greater than' or `less than' another. These concepts are
pretty easy to understand if we are just dealing with integers, but what
if we want the tree to store data of some complex type, such as student
records? How can we determine the ordering of such objects? In Java, and
other object-oriented languages, the usual solution is to have the data
objects implement a method that compares the object with another of the
same type, and returns some indication of which object is `greater'. For
example, the compareTo methods from the built-in
String class or the Person class from Lab
16.
We also want our trees to be generic; this is, we should be able to
construct a tree holding any type of ordered data without changing the
implementation of the binary tree class itself. To achieve both of these
goals using Java, the first step is to define an interface class,
declaring the methods that we want all tree data objects to
implements. Remember that an interface only supplies method headers; the
bodies of the methods must be provided by the class(es) that implement the
interface.
1 /**
2 * Allows a class to define an ordering on its instances.
3 */
4 public interface OrderedObject {
5
6 /**
7 * Compare the value of this object with the value of other. Returns:
8 * -1 if this object's value is 'less than' other's value
9 * 0 if the two object's values are equal (equals() would return true)
10 * 1 if this object's value is 'greater than' other's value
11 * Throws an OrderedObjectException if the values cannot be compared.
12 */
13 int compareTo(OrderedObject other) throws OrderedObjectException;
14 }
Every class that implements this interface must provide a
compareTo method with the specified arguments and return
type. In object-oriented terms, every instance if a class that implements
OrderedObject is-a OrderedObject and is
therefore suitable as a data object type for the BinaryTree
class. The OrderedString class below shows a simple example
of this interface in action:
1 /**
2 * Transforms a String into an OrderedObject.
3 */
4 class OrderedString implements OrderedObject {
5
6 // The actual string data
7 private String str;
8
9
10 /** Create a new OrderedString encapsulating the given String */
11 public OrderedString(String value) {
12 str = value;
13 }
14
15
16 /** Implement the method from the OrderedObject interface */
17 public int compareTo(OrderedObject other) throws OrderedObjectException {
18 if (other instanceof OrderedString) {
19 return str.compareTo(((OrderedString)other).str);
20 }
21 else {
22 throw new OrderedObjectException("Illegal comparison");
23 }
24 }
25
26
27 /** Produce a printable representation of this object */
28 public String toString() {
29 return str;
30 }
31 }
Instances of the OrderedString class act as `wrappers' around
ordinary String objects, and implement the required method
from the OrderedObject interface. You might think that since
String already has a suitable compareTo method
-- line 19 above simply calls this existing method to perform the
comparison -- we would have been better off to just extend the
String class rather than storing the String as
an instance variable. Well, you're right, it would have been much more
elegant to do it this way. However, the built in String
class is declared to be a final class, meaning that it cannot
be extended. An oversight on the part of the Java designers?
While this technique for creating ordered object classes is convenient and
reasonably elegant, it is not without its drawbacks. The
compareTo method must explicitly check that the
other argument is in fact an instance of
OrderedString and not some other type of
OrderedObject. (Something to think about: why can we not
just declare the method to take an OrderedString
parameter?) Even with this check in place, it is still possible to
construct a tree from a mixture of different OrderedObject
implementations; searches or insertions on such a tree might then
mysteriously fail. To work around this problem, we can extend the
BinaryTree class itself to accept only
OrderedString objects:
1 /**
2 * A tree that enforces the use of OrderedStrings.
3 */
4 public class StringTree extends BinaryTree {
5
6 /** Insert an OrderedString into the tree */
7 public void insert(OrderedString newData) throws TreeException {
8 try {
9 super.insert(newData);
10 }
11 catch (OrderedObjectException e) { }
12 }
13
14 /** Don't allow a non-OrderedString to be inserted */
15 public void insert(OrderedObject newData) throws TreeException {
16 throw new TreeException("Attempt to insert a non-OrderedString");
17 }
18
19
20 /** Look for the given OrderedString */
21 public BinaryTree find(OrderedString target) throws TreeException {
22 try {
23 return super.find(target);
24 }
25 catch (OrderedObjectException e) { return null; }
26 }
27
28 /** Don't allow searches for non-OrderedStrings */
29 public BinaryTree find(OrderedObject target) throws TreeException {
30 throw new TreeException("Attempt to search for a non-OrderedString");
31 }
32 }
We will now return to discussing the algorithm for inserting new nodes
into the tree. The insert method as implemented in lines
46-68 of BinaryTree.java is recursive. There are two base
cases that cause the recursion to terminate:
-
The root of the tree contains no data (the
data field is
null). In this case, the new data is placed in the root
node of the tree. As we shall see later, such an `empty' node will
only occur at a suitable point in the tree.
-
The root of the tree contains the same data (as determined by
compareTo) as the data we are inserting. This
implementation requires that data items be unique, so in this case we
throw a TreeException and the insertion fails.
If neither of these cases occurs, the root node must contain data that is
either less than or greater than newData, again as determined
by compareTo. The method then makes a recursive call to
insert, passing the right or left subtree respectively as the
root of the tree to insert into. If the target subtree does not yet exist
(the subtree reference is null), a new, empty tree is created
and attached to the current root node. Since such a node will contain no
data, the recursive call will stop at the first base case above and insert
the data at that point.
For example, assume we have just created a new BinaryTree
object, resulting in the structure seen in Figure 2:
BinaryTree tree = new BinaryTree();
Figure 2.
We now attempt to insert the integer value 19, wrapped inside
an OrderedInteger object, into the tree:
tree.insert(new OrderedInteger(19));
The insert method will immediately find that the root node of
the tree contains no data, and will insert the data value there, giving
the new structure shown in Figure 3:
Figure 3.
Next, we attempt to insert the value 10:
tree.insert(new OrderedInteger(10));
This time, the root of the tree is occupied, so the method must
recursively call insert on either its left or right subtree.
The value to be inserted (10) is less than the value in the
root (19), so it must be placed in the left subtree.
However, that subtree does not yet exist, so it must be created (Figure
4):
Figure 4.
Then, the recursive call to insert will have the newly
created left hand subtree as its root node. Since the node is empty, the
new value can immediately be inserted (Figure 5):
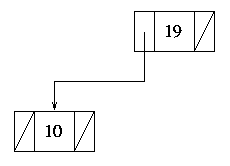
Figure 5.
Several more insertions might lead to the structure shown in Figure
6:
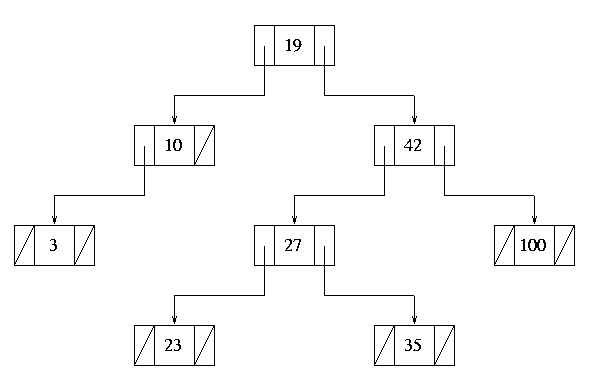
Figure 6.
The find method is structurally very similar to
insert, using the same recursive algorithm to locate the
required data, if it exists. Of course, both methods could easily be
rewritten in a purely iterative way without any recursive calls (you may
want to try doing this). Also, the same basic algorithms could be used
equally well to perform inserts and searches on an ordered linked list
structure; this case the left and right `subtrees' would be represented by
the left and right halves of the list.
Traversing the tree
Once we have some data in our tree, it might be useful to be able to list
the data out in some sequential order, perhaps in order to write it to a
disk file, or to print out a listing of the database contents. Unlike a
list, it is not immediately obvious in what order we should visit the tree
nodes to achieve this, as each node has two subtrees as well as the
data contained in the node itself. (Note: a sorted list can be considered
as a `degenerate' tree, where each node has a right hand subtree only).
As it happens, there are three common orderings -- the process of visiting
every tree node in some order is often referred to as traversing
the tree -- that adapt well to the tree structure: pre-ordering,
post-ordering and in-ordering. The names relate to the
relative ordering of the node data and subtrees. These three traversal
strategies will be illustrated with reference to the tree shown in Figure
7.
Figure 7.
Pre-ordering
In this ordering scheme, the data stored in each node is ordered
before the contents of its left and right subtrees. That is, each
node is traversed in the order [node data, left subtree data, right
subtree data]. The traversal is done recursively on the subtrees. A
pre-order traversal of Figure 7 would proceed as follows:
19, 10, 3, 42
Post-ordering
In the post-ordering scheme, each node is traversed in the order [left
subtree data, right subtree data, node data]:
3, 10, 42, 19
In-ordering
Under the in-ordering scheme, each node in the tree is traversed in the
order [left subtree data, node data, right subtree data]. Because all of
the data in the left hand subtree is less than the root node data, and all
the data in the right hand subtree is greater than the root data, this
algorithm results in the tree data being printed 'in order':
3, 10, 19, 42
The TreeTest class given below includes methods to traverse a
tree using each of these orderings.
1 import java.util.Enumeration;
2
3 class TreeTest {
4
5 public static void main(String[] args) {
6 BinaryTree tree = new BinaryTree();
7
8 try {
9 // Insert A-Z in some random order
10 java.util.Vector v = new java.util.Vector();
11 for (char c = 'A'; c <= 'Z'; c++) {
12 v.addElement(new Character(c));
13 }
14 while (v.size() > 0) {
15 int r = (int)Math.round(Math.random() * (v.size()-1));
16 tree.insert(new OrderedString(v.elementAt(r).toString()));
17 v.removeElementAt(r);
18 }
19 printPreOrder(tree);
20 System.out.println();
21 }
22 catch (Exception e) {
23 System.out.println(e);
24 }
25 }
26
27
28 public static void printPreOrder(BinaryTree tree) {
29 if (tree.data() != null) {
30 System.out.print(tree.data()+" ");
31 }
32 if (tree.left() != null) {
33 printPreOrder(tree.left());
34 }
35 if (tree.right() != null) {
36 printPreOrder(tree.right());
37 }
38 }
39
40 public static void printPostOrder(BinaryTree tree) {
41 if (tree.left() != null) {
42 printPostOrder(tree.left());
43 }
44 if (tree.right() != null) {
45 printPostOrder(tree.right());
46 }
47 if (tree.data() != null) {
48 System.out.print(tree.data()+" ");
49 }
50 }
51
52 public static void printInOrder(BinaryTree tree) {
53 if (tree.left() != null) {
54 printInOrder(tree.left());
55 }
56 if (tree.data() != null) {
57 System.out.print(tree.data()+" ");
58 }
59 if (tree.right() != null) {
60 printInOrder(tree.right());
61 }
62 }
63 }
Why would you choose one traversal method over another? Clearly an
in-order traversal is appropriate when you want to retrieve the tree data
in sorted order. However, consider the case where the tree contents are
to be stored in a file, then later reloaded into a new tree structure. If
in-order traversal was used to write the file, the data ends up being
pre-sorted when the time comes to load it back in again. Consider for a
moment what the tree structure will look like if the data to be inserted
is already sorted...essentially the tree degrades into a linked list,
neatly eliminating any advantage from using the tree! In this situation,
you want the data to be unsorted, so a pre- or post-order traversal
would be used when writing the file.
Deleting nodes
Deleting nodes from a tree is somewhat more complicated than deleting from
a linked list. The problems arise because the node being deleted may have
two (or even more) 'children', all of which must be attached to a suitable
'parent' node when their existing parent is removed. The rearrangement of
the tree must be done in such a way as to maintain the correct ordering of
each node's subtrees. The class below adds a delete method
to the basic binary tree, illustrating one of the many ways this can be
achieved. The new method makes use of an additional private method which
takes a third parameter. This parent argument gives the
parent node of the tree parameter. It is initialised to
null by the main delete method, since we have no
way of knowing whether or not the tree has a parent node.
1 /**
2 * An extended binary tree, able to delete nodes as well (Wow!)
3 */
4 public class DeletingBinaryTree extends IteratingBinaryTree {
5
6 /** Delete a node matching oldData */
7 public boolean delete(OrderedObject oldData) throws TreeException, OrderedObjectException {
8 return delete(this, null, oldData);
9 }
10
11 // A far-too-complex subroutine to do the real work!
12 private boolean delete(BinaryTree tree, BinaryTree parent, OrderedObject oldData) throws TreeException, OrderedObjectException {
13 if (tree.data != null) {
14 int a = oldData.compareTo(tree.data);
15 if (a < 0) {
16 return (tree.left == null) ? false : delete(tree.left, tree, oldData);
17 }
18 else if (a > 0) {
19 return (tree.right == null) ? false : delete(tree.right, tree, oldData);
20 }
21 else {
22 // found it, now delete it
23 if (tree.left == null && tree.right == null) {
24 // Leaf node
25 if (parent != null) {
26 // If we have a parent we can just snip the node off
27 if (parent.left == tree) {
28 parent.left = null;
29 }
30 else {
31 parent.right = null;
32 }
33 }
34 else {
35 // Otherwise we get left with an empty node
36 tree.data = null;
37 }
38 }
39 else if (tree.left == null) {
40 // Replace the node with its right-hand child
41 tree.data = tree.right.data;
42 tree.left = tree.right.left;
43 tree.right = tree.right.right;
44 }
45 else if (tree.right == null) {
46 // Replace the node with its left-hand child
47 tree.data = tree.left.data;
48 tree.right = tree.left.right;
49 tree.left = tree.left.left;
50 }
51 else {
52 // Find the largest node on the LHS
53 BinaryTree max = tree.left;
54 while (max.right != null) {
55 max = max.right;
56 }
57 // Move LHS up to root, attach old RHS to max
58 max.right = tree.right;
59 tree.data = tree.left.data;
60 tree.right = tree.left.right;
61 tree.left = tree.left.left;
62 }
63 return true;
64 }
65 }
66 else {
67 return false;
68 }
69 }
70 }
The private delete method uses the familiar recursive
searching technique to locate the node to be deleted. Not that the
parent parameter is updated each time a new recursive call is
made. Eventually, the target node will be found, or the search will reach
the leaves of the tree and return false.
Once the node has been found, we must disconnect it from the tree
structure. This operation is handled as four separate cases, based on the
number and location of the node's children.
Case 1: No children
Deleting a leaf node is by far the easiest case to handle, since there are
no child nodes to be rearranged. If we know the parent of the target
node, the left or right subtree (whichever points to the target) of the
parent is simply set to null. If the parent is unknown, the
node cannot be disconnected, but we can set its data member
to null, turning it into an empty node that may be reused by
a subsequent insert operation. Figure 9 shows the result of deleting the
node containing value 100 from the tree in Figure 6:
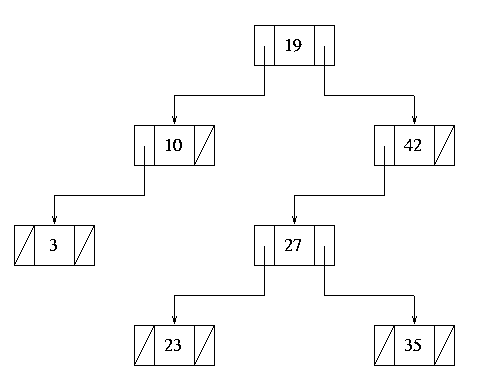
Figure 8.
Case 2: Left subtree only
This case is also relatively trivial to deal with. All of the nodes on
the left subtree of the target must be 'less than' the target node; they
must also be 'less than' the target node's parent, if it has one.
Therefore, we can just replace the target node with its left-hand subtree
to both delete the target and maintain the correct sorting relationships
in the tree. Figure 9 shows the result of deleting the node containing
value 10 from the tree in Figure 6:
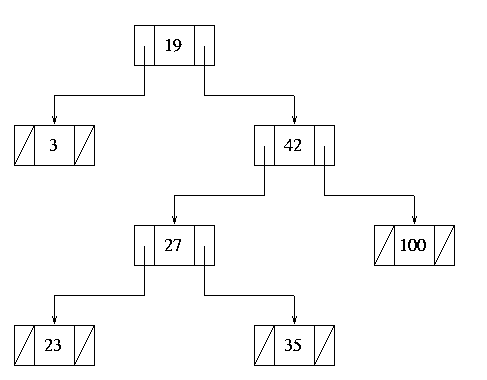
Figure 9.
Case 3: Right subtree only
This case exactly analagous to the previous one, except that the target
node will be replaced with its right subtree.
Case 4: Left and right subtrees
This is the most complicated situation to deal with, since both subtrees
must be reattached somewhere while maintaining the sorting
relationship of the tree. The trick is to make a couple of observations
about the properties of the two subtrees:
-
Every node in the right subtree is 'greater than' every node in the
left subtree.
-
The 'largest' node in the left subtree cannot have a right
subtree, because any nodes on such a subtree would be larger than
their parent.
Therefore, we know that there is at least one place in the left subtree
where we could 'attach' another subtree, as long as all the nodes in the
subtree are 'greater than' the 'greatest' node on the left subtree. The
right subtree of the target node meets this condition, since all of
its nodes must be greater than anything on the left subtree. So,
the first step in deleting the target node is to disconnect its right
subtree, then reconnect the subtree as the right subtree of the largest
node in the left subtree. This is much easier to visualise than to
explain -- Figure 10 shows the first step in deleting the node containing
19 from the tree of Figure 6:
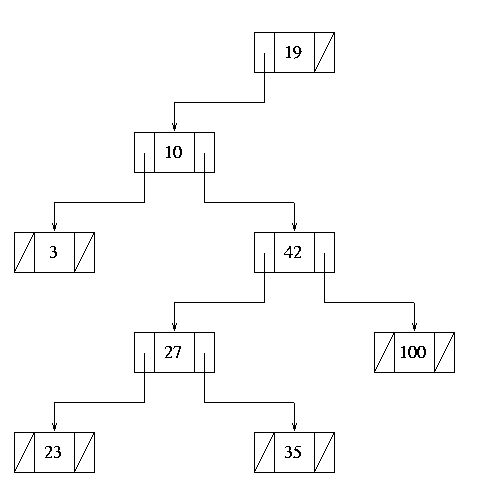
Figure 10.
The tree at this point is not internally consistent (there are nodes on
the left subtree of the target that are definitely 'greater than'
19). This is not really a problem though, since we are about
to delete the target node. At this point the problem will look exactly
like case 2 above, where the target node has only a left subtree. This,
we simply replace the target with its new left subtree, and the deletion
is complete:
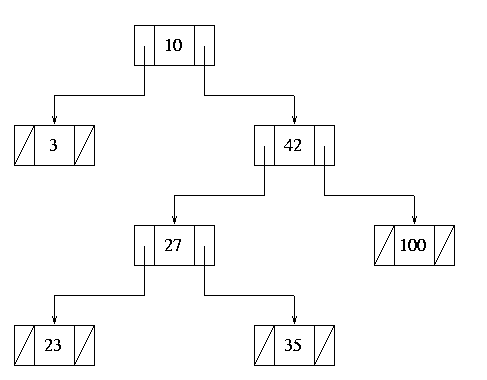
Figure 11.
The algorithm used by the DeletingTree class contains a
subtle bug. It it worthwhile trying to figure out what this bug is, and
to develop a solution for it. (Hint: consider what could happen after a
'case 1' deletion has left an empty node in the tree, and the empty node's
parent is then deleted).
Using Iterators for tree traversal
The final section of these notes presents an alternative technique for
traversing a tree, or in indeed any other data structure. The class below
extends the basic binary tree class with the capability to create
so-called iterator or enumerator objects that may then be
used to traverse the tree in a particular way. An iterator is, as the
name implies, an object that iterates over all of the members of some data
structure, returning them to the user one at a time in some defined order.
The advantage of using an iterator rather than coding the traversal
methods yourself (as in the TreeTest program is that you do
not need to know anything about the internal structure of the tree, list,
etc that you are traversing -- the iterator object will keep track of all
these details for you.
The iterators used by the IteratingBinaryTree are based
around the Java Enumeration interface, which essentially
provides a general framework for building iterator objects. An instance
of Enumeration must provide two methods:
-
boolean hasMoreElements() returns true iff
there are elements that have yet to be traversed.
-
Object nextElement() returns the next object in the
traversal. Note that this object is of class Object and
must be cast to an appropriate type.
An extended implementation of Enumeration might offer
additional methods, eg. to 'rewind' the traversal back to the first
element. Many Java classes, such as Vector and
Hashtable provide methods to obtain an
Enumeration object over their elements. In general an
Enumeration will be used in a loop such as:
Enumeration e = someObject.elements();
while (e.hasMoreElements()) {
someClass next = (someClass)e.nextElement();
System.out.println(next);
}
The IteratingBinaryTree class contains four inner classes
that implement the iterators for the tree. The most important of these is
the TreeIterator class. This declares a Vector
object (Java's built-in linked list class) that will hold the elements of
the tree in traversal order, and implements the Enumeration
methods that will return these elements on at a time, in the order they
occur in the vector. It is up to the subclasses of
TreeIterator to fill in the contents of the vector.
Three subclasses of TreeIterator are provided, to perform
pre-, post- and in-order traversals of the tree. Each of these performs
the traversal in the usual way and places the tree data into the vector in
the order that the nodes were traversed. Thus, the user will be able to
retrieve the tree data in the same order using the
nextElement() method of the iterator. The
IteratingBinaryTree class itself hass three new methods to
create and return the three kinds of iterator. Note that all of these
iterator classes take a copy of the tree contents, so any additions
or deletions made to the tree should not affect any active iterators. Is
this always true? In particular, is there any way that a deletion (using
the algorithm presented above) could affect the contents of a tree
iterator? (Hint: is the data really copied, or just aliased?)
1 import java.util.Enumeration;
2 import java.util.Vector;
3 import java.util.NoSuchElementException;
4
5
6 /**
7 * A simple binary tree class, storing instances of OrderedObject.
8 */
9 public class IteratingBinaryTree extends BinaryTree{
10
11 // A basic iterator over a vector of objects
12 private class TreeIterator implements Enumeration {
13 private Vector data;
14 private int current;
15
16 TreeIterator() {
17 data = new Vector();
18 current = 0;
19 }
20
21 public boolean hasMoreElements() {
22 return (current < data.size());
23 }
24
25 public Object nextElement() {
26 if (hasMoreElements()) {
27 return data.elementAt(current++);
28 }
29 else {
30 throw new NoSuchElementException();
31 }
32 }
33 }
34
35 // An iterator containing the tree data in pre-order
36 private class PreOrderIterator extends TreeIterator {
37
38 PreOrderIterator(BinaryTree tree) {
39 init(tree);
40 }
41
42 private void init(BinaryTree tree) {
43 if (tree.data() != null) {
44 this.data.addElement(tree.data());
45 }
46 if (tree.left() != null) {
47 init(tree.left());
48 }
49 if (tree.right() != null) {
50 init(tree.right());
51 }
52 }
53 }
54
55 // An iterator containing the tree data in post-order
56 private class PostOrderIterator extends TreeIterator {
57
58 PostOrderIterator(BinaryTree tree) {
59 init(tree);
60 }
61
62 private void init(BinaryTree tree) {
63 if (tree.left() != null) {
64 init(tree.left());
65 }
66 if (tree.right() != null) {
67 init(tree.right());
68 }
69 if (tree.data() != null) {
70 this.data.addElement(tree.data());
71 }
72 }
73 }
74
75 // An iterator containing the tree data in order
76 private class InOrderIterator extends TreeIterator {
77
78 InOrderIterator(BinaryTree tree) {
79 init(tree);
80 }
81
82 private void init(BinaryTree tree) {
83 if (tree.left() != null) {
84 init(tree.left());
85 }
86 if (tree.data() != null) {
87 this.data.addElement(tree.data());
88 }
89 if (tree.right() != null) {
90 init(tree.right());
91 }
92 }
93 }
94
95
96 /** Return a pre-order iterator for this tree */
97 public Enumeration iteratePreOrder() {
98 return new PreOrderIterator(this);
99 }
100
101 /** Return a post-order iterator for this tree */
102 public Enumeration iteratePostOrder() {
103 return new PostOrderIterator(this);
104 }
105
106 /** Return an in-order iterator for this tree */
107 public Enumeration iterateInOrder() {
108 return new InOrderIterator(this);
109 }
110 }
The program TreeTest2 below is a simple demonstration of the
iterator classes in use. You shoud modify this to experiment with the
pre- and post-order iterators as well.
1 import java.util.Enumeration;
2
3 class TreeTest2 {
4
5 public static void main(String[] args) {
6 IteratingBinaryTree tree = new IteratingBinaryTree();
7
8 try {
9 // Insert A-Z in some random order
10 java.util.Vector v = new java.util.Vector();
11 for (char c = 'A'; c <= 'Z'; c++) {
12 v.addElement(new Character(c));
13 }
14 while (v.size() > 0) {
15 int r = (int)Math.round(Math.random() * (v.size()-1));
16 tree.insert(new OrderedString(v.elementAt(r).toString()));
17 v.removeElementAt(r);
18 }
19 Enumeration enum = tree.iterateInOrder();
20 while (enum.hasMoreElements()) {
21 System.out.print(enum.nextElement()+" ");
22 }
23 System.out.println();
24 }
25 catch (Exception e) {
26 System.out.println(e);
27 }
28 }
29 }
Scott Mitchell
Last
modified: Mon May 24 15:56:08 BST 1999