Operations involving the whole of a tree are difficult to program without using recursion. But more generally, operations on linked data structures are often as easily programmed using recursion than using iteration, even when there's no particular difficulty involved in using iteration. There's no "right" or "wrong" way of doing it, but one you get comfortable with using recursion, it is often easier to write methods that way and understand methods written using recursion, than it is to write and understand methods that do the same thing expressed with iteration.
To demonstrate this, we will go back to the implementation of sets using ordered linked lists, but this time use recursion to code the methods. Here is the code to delete an element from an ordered linked list representing a set:
public void delete(int n)
{
if(list!=null)
if(list.first==n)
list=list.next;
else
delete(n,list);
}
private static void delete(int n,Cell l)
{
if(l.next!=null)
if(l.next.first==n)
l.next=l.next.next;
else if(l.next.first<n)
delete(n,l.next);
}
This uses the same technique we saw with printing trees. There is a public
non-static method which refers to the field from the object the method
is called on, in this case the field list. But most
of the work is done by a private static method where the structure being
manipulated is passed as a parameter. Since the type of this method's
second parameter is defined by a class which is private inside the class
where the method occurs, it could not be anything other than private,
since outside the class it could not have anything to be its second
argument.
Note that we cannot actually change the object the field list
refers to in a method which takes it as a parameter. We can only
change the contents of the object, including fields which refer to further
objects. To illustrate this, suppose we mistakenly used the following
code:
public void delete(int n)
{
delete(n,list);
}
private static void delete(int n,Cell l)
{
if(l!=null)
if(l.first==n)
l=l.next;
else if(l.first<n)
delete(n,l.next);
}
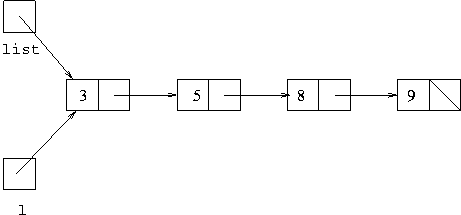
then if we have the list [3,5,8,9] and we want
to delete 3 from it, when we start the static delete method we have
the situation (where list is a set object field, but
l is a local variable in the method delete):
When we then execute l=l.next we get to the situation:
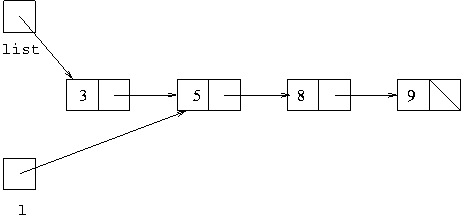
Which has changed what the local variable l refers to,
but has made no change to the list field of the object.
If we wish to delete 5, however, from the situation in the first figure
above, executing l.next=l.next.next will result in the
situation:
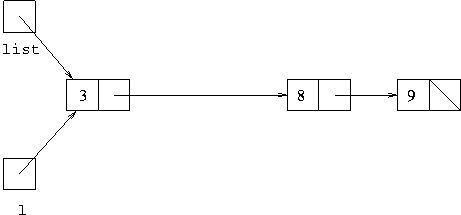
which does result in a change to the list referred to by the object
field list.
In a similar way, when we are adding an element to the list, we deal with adding it to the front in separate code in the first (non-static) method, while adding elements otherwise in the static recursive method:
public void add(int n)
{
if(list==null)
list = new Cell(n,null);
else if(n<list.first)
list = new Cell(n,list);
else
add(n,list);
}
private static void add(int n,Cell l)
{
if(l.next==null||n<l.next.first)
l.next = new Cell(n,l.next);
else if(n>l.next.first)
add(n,l.next);
}
In the static recursive methods delete and add
the assumption is made that the integer to be deleted or to be added before
occurs after the integer in the cell immediately referred to by the
parameter l. If the integer to be deleted is not the next
cell, or the integer before which the new cell is to be added is not the
next cell, the manipulation is equivalent to manipulating the list
following that referred to by l so can be done by a
recursive call. As we are dealing with ordered lists, the place to add
a new integer is just before the first integer which is greater than it.
But if the number being added is greater than any number in the list, then
it's just after the last number in the list. That is what the lines
if(l.next==null||n<l.next.first)
l.next = new Cell(n,l.next);
accomplish in the static method add. Here the "short-circuit"
operation of || is essential. If l.next is
null then there is no such field as l.next.first
and attempting to access it would cause an exception. However,
a||b for any expressions a
and b is defined as evaluating a
and if it evaluates to true returning true without
evaluating b. Therefore if l.next==null
evaluates to true, the whole expression
l.next==null||n<l.next.first evaluates to true
without n<l.next.first being evaluated at all.
Another way of dealing with the fact that we need special code to deal with manipulating the list when the manipulation takes place at the front of the list is to use a "dummy element". So, for example, the following structure:

would represent the set {3,7,8}
with the content of the first cell being irrelevant. In that case,
the public methods for add and delete
could be just:
public void delete(int n)
{
delete(n,list);
}
public void add(int n)
{
add(n,list);
}
If this representation were used, the class would have to have a
constructor which set up the dummy first element when a new set
object was created:
public IntSet15()
{
list = new Cell(0,null);
}
With delete, since the list is ordered, if it is found that
the next number in the list is greater than the number being deleted, the
number being deleted cannot be in the list so nothing more needs to be
done. If we wanted to make quite clear it was understood this is what
happens, we could write the code:
private static void delete(int n,Cell l)
{
if(l!=null)
if(l.first==n)
l=l.next;
else if(l.first<n)
delete(n,l.next);
else ; // Do nothing - n not found
}
The semicolon after the final else indicates the
"empty statement", the statement with nothing in it. This has
no effect on how the code is executed, but makes it more clear to
the human reader of the code.
Similarly, in the code for add it might be a good idea
to add an empty statement and a comment to indicate that in the
case where we are adding a number to the list and find the number is
already in the list, we do nothing, so:
private static void add(int n,Cell l)
{
if(l.next==null||n<l.next.first)
l.next = new Cell(n,l.next);
else if(n>l.next.first)
add(n,l.next);
else ; // Do nothing - n already in list
}
Now if we wanted to change the behaviour of sets to report some sort of
special condition (maybe throw an exception) if a number being deleted
isn't in the list, or a number being added is already in the list, it is
easier to see where the change in the code should be made.
The recursive code for list membership is easy, and since it doesn't involve changing the structure of the list, it doesn't require any code to handle the special case of making changes at the beginning of the list. So here's the code:
public boolean member(int n)
{
return member(n,list);
}
private static boolean member(int n,Cell l)
{
if(l==null||n<l.first)
return false;
else if(n==l.first)
return true;
else
return member(n,l.next);
}
The nice thing about this is that the code which actually solves it
is close to an abstract specification of the solution to the problem.
A number is not a member of an ordered list if the list
is null or the number is smaller than the first element
in the list. A number is and element of a list if it is the
first number in the list. A number is an element of a list
if it is an element of the list which forms the next
field of the original list. We can see that this is logically true,
and that the code directly reflects these English statements.
Recursive code can also be given for converting a list of integers representing a set to a string:
public String toString()
{
if(list==null)
return "{}";
else
return "{"+toString(list)+"}";
}
private static String toString(Cell l)
{
if(l.next==null)
return ""+l.first;
else
return l.first+","+toString(l.next);
}
One interesting thing here is that if the last but one line is changed to:
return toString(l.next)+","+l.first;
the numbers are returned for printing in descending rather than
ascending numerical order. With trees, we discussed three different
ways of going through the elements of a tree -
inorder, preorder and postorder.
This depended on the ordering of considering the node of the tree and
considering its branches. Actually, there are six different ways of
traversing a tree using straightforward recursion, because the three
ways we gave all considered the left subtree before the right, so there
is the equivalent for each with the recursive call on the right subtree
coming before the recursive call on the left. With lists there are just
two orderings - either consider the first element then consider the
rest through the recursive call, or do the recursive call first.
Considering the first element after the recursive call will mean the
second element is considered after considering all but the first two
elements but before the first, and so on, so in general considering the
first element afer the recursive call results in the elements being
considered in backward order to their position in the list.
Copying linked lists is very easily done recusively. Thinking recursively,
if a linked list is null, its copy is null,
otherwise its copy is a new cell whose first item is the
first item from the original list, and whose next is a
copy of the rest of the original list. This gives the following
code to copy a linked list:
private static Cell copy(Cell l)
{
if(l==null)
return null;
else
{
List l1 = copy(l.next);
return new Cell(l.first,l1);
}
}
which could be used with the method
public IntSet11a copy()
{
Cell list1 = copy(list);
return new IntSet11a(list1);
}
to give alternative, and perhaps easier to understand, code for a
copy method for sets implemented by linked lists than that given
previously.
member implemented using
recursion, assuming the previous
representation of sets using ordered trees:
public boolean member(int n)
{
return member(n,tree);
}
private static boolean member(int n,Cell t)
{
if(t==null)
return false;
else if(t.item==n)
return true;
else if(n<t.item)
return member(n,t.left);
else
return member(n,t.right);
}
As with lists, there is a public non-static method which calls a
private static method taking the field of the object as its argument.
As with lists, the code for member almost matches a
declaration of what it is to be a member of an ordered tree. An
integer is not a member of a tree if the tree is
null. An integer is a member of a tree if
it is equal to the node value of the tree. An integer is a member
of the tree if it is a member of its left subtree. An integer is a
member of a tree if it is a member of its right subtree. And an integer
will only be a member of the left subtree if it is less than the node
value of the tree, and will only be a member of the right subtree if it
is greater than the node value of the tree (so there is no need in
either case to search for membership of the other branch).
Here is the code to add an element to a sorted binary tree:
public void add(int n)
{
if(tree==null)
tree = new Cell(n,null,null);
else
add(n,tree);
}
private static void add(int n,Cell t)
{
if(n<t.item)
if(t.left==null)
t.left = new Cell(n,null,null);
else
add(n,t.left);
else if(n>t.item)
if(t.right==null)
t.right = new Cell(n,null,null);
else
add(n,t.right);
else ; // Do nothing if n is already in the tree
}
The "do nothing" line is added at the end, as we saw with lists, just
to make it clear to the human reader of the code that it is intentional
that no change is made to the tree if it is found the number that
was to be added is already present. As with lists, we need special
code to deal with adding something to the top of the tree, but here
that only happens when the tree is null. Otherwise, to
add something to a tree, you add it to the left branch if it is less
than the node value of the tree, and to the right branch if it is
greater. Adding an element to a null branch of the tree
means replacing that branch by a leaf, that is a tree whose node value
is the element and whose left and right subtrees are null.
But that must be done in a method call where the parent of the null
branch is the parameter to make the change permanent in the whole tree.
Deleting an element from a tree is again fairly complex due to the code
which is necessary to fill a "hole" where the element that is deleted
is in a cell which has left and right subtrees which are not
null. Here is the code for it:
private static void delete(int n,Cell t)
{
if(n<t.item)
if(t.left.left==null&&t.left.right==null)
if(t.left.item==n)
t.left=null;
else ; // Do nothing - n not found in t
else
delete(n,t.left);
else if(n>t.item)
if(t.right.left==null&&t.right.right==null)
if(t.right.item==n)
t.right=null;
else ; // Do nothing - n not found in t
else
delete(n,t.right);
else if(t.left==null)
{
t.item=t.right.item;
t.right=t.right.right;
}
else if(t.left.right==null)
{
t.item=t.left.item;
t.left=t.left.left;
}
else
t.item = removeRightmost(t.left);
}
private static int removeRightmost(Cell t)
{
if(t.right.right==null)
{
int rightmost = t.right.item;
t.right = t.right.left;
return rightmost;
}
else
return removeRightmost(t.right);
}
Here the method removeRightmost performs two tasks.
It finds and returns the largest integer in the tree t
which it takes as an argument (which must also be the rightmost
integer in that tree) and it also alters the tree t so
that the cell storing that integer is removed. This is used to "fill the
hole" produced by deleting an integer, as we did with the same operation
expressed iteratively.
To remove the rightmost element from a tree t, if
t's right branch is a tree with null as its
right branch, then t's right branch is set to the left
branch of its right branch (since that need not be null),
and the node value of that right branch is returned as the rightmost
value in the tree. Otherwise, to remove the rightmost element from the
tree, we have to remove the rightmost element from its right branch.
The code for removeRightmost assumes that the
tree t which is passed to it as its argument does not
have null as its right subtree. This means that the
method delete has to have a special section of code to
deal with the case where the number being removed is the node value of
the tree t passed as its argument, but the right subtree of
the left subtree of t is null.
With the method delete, the right or left branch is
removed if it is a leaf and contains the integer to be deleted. Otherwise
if the item to be deleted is not the node value of the tree that was
the argument to the call of delete, a call of
delete to delete that item from the left or right branch is
made as appropriate.
Note that if the first part of the code for delete were
not written:
if(n<t.item)
if(t.left.left==null&&t.left.right==null)
if(t.left.item==n)
t.left=null;
else ; // Do nothing - n not found in t
else
delete(n,t.left);
it would have to be written:
if(n<t.item)
if(t.left.left==null&&t.left.right==null)
{
if(t.left.item==n)
t.left=null;
}
else
delete(n,t.left);
In the first case, the else in the fifth line matches the
if in the third line. This else is not
needed, because there is no action if the condition in its matching
if is false. It is put there just to make
a little clearer, as shown also by the comment, that this is the point
where nothing is done because the integer n has been
found not to be in the tree. The curly brackets are needed in the
second case because the if inside them has no matching
else. Without the curly brackets blocking off
if(t.left.item==n) t.left=null;as a separate statement on its own, the following
else
would be taken to match this if and not the if
before it. This is known as the dangling else situation, and
can occasionally be the cause of unexpected errors in a program. It
is important here to remember that the indentation we use in Java is only
to make the code easier for us to read, it has no meaning in Java itself.
So the (wrong, so put in italics to show that) code:
if(n<t.item)
if(t.left.left==null&&t.left.right==null)
if(t.left.item==n)
t.left=null;
else
delete(n,t.left);
would actually be interpreted by the Java compiler as what we would write:
if(n<t.item)
if(t.left.left==null&&t.left.right==null)
if(t.left.item==n)
t.left=null;
else
delete(n,t.left);
Since Java itself gives no special meaning to indentation, it will not
match an else to an if before the previous
unmatched if just because we line it up underneath the
earlier if using indentation.
Last modified: 6 February 2003